Vault як пам'ять агента: чому мій AI-агент не забуває
Кожна розмова з LLM закінчується — і агент забуває все. Я вирішив це не «вирішувати». Я вирішив зробити vault пам'яттю, яка не залежить від контексту розмови.



← Серія статей: Мій AI-агент
Проблема з пам'яттю у LLM
LLM (велика мовна модель — AI типу ChatGPT або Claude) має одну фундаментальну особливість: не пам'ятає нічого між сесіями. Кожна нова розмова — чистий аркуш. Ти пояснюєш контекст знову. Агент не знає що вчора ви вирішили X, а позавчора відклали Y.
Класичне рішення — vector database. Беремо нотатки, перетворюємо кожну в числовий «відбиток» (embedding — спосіб описати зміст тексту числами), при кожному запиті знаходимо найближчі за змістом фрагменти і підставляємо їх у prompt. Це називається RAG — Retrieval-Augmented Generation, «пошук + генерація».
Я так не зробив.
Не тому що не знаю як — тому що протестував інший підхід і він спрацював краще для моєї задачі. Агент читає vault структуровано, ітеративно, з конкретними якорями — і отримує релевантний контекст без жодних embeddings.
Це вимагало правильно організованого vault'у. Vault — папка з текстовими файлами (у моєму випадку Obsidian). Не база даних, не хмарний сервіс — звичайні markdown-файли на диску.
Другий закон конституції: vault як джерело істини
У Частині 2 я описав конституцію агента — три правила за якими він живе: чеснота понад усе, vault як джерело істини, безпечні кордони. Ось друге з них.
Другий закон Сюзанни простий: vault важливіший за пам'ять агента.
Якщо в пам'яті є одна версія факту, а у vault — інша, vault виграє. Завжди.
Практично це означає: агент не покладається на «пам'ять» у звичному значенні. Він не зберігає факти у власній persistent memory думаючи «я це пам'ятаю». Він читає vault щоразу. Vault — єдине місце де факти зберігаються офіційно.
Vault зберігається у git — системі контролю версій яка фіксує кожну зміну файлу з датою і автором. Git не забуває.
Це вирішує дрейф пам'яті через архітектуру, а не через правила.
Як агент дізнається що відбулось поки його не було?
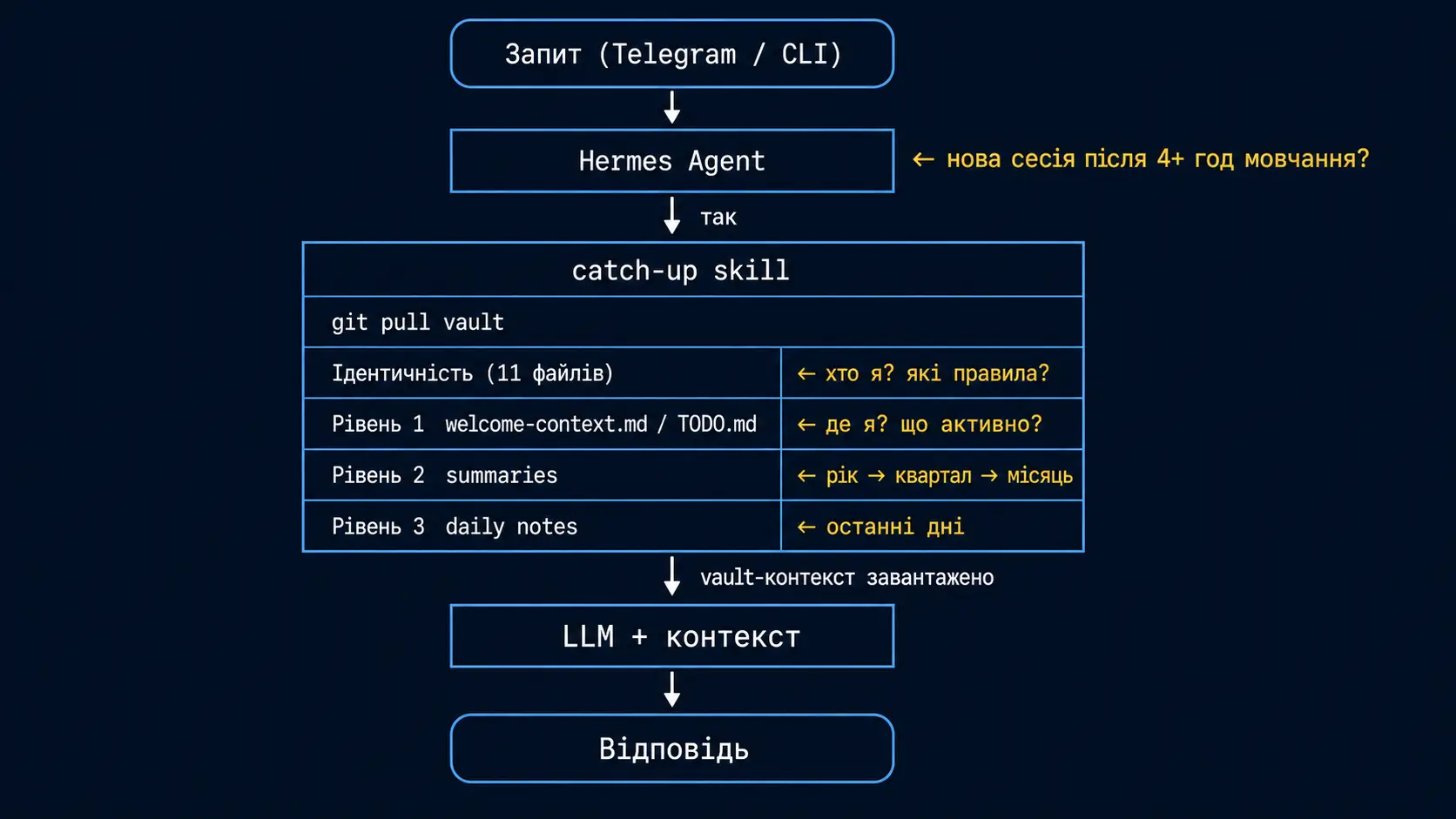
Сюзанна — ім'я мого агента (детальніше про її характер і правила — у Частині 2). Hermes — платформа на якій вона живе: скрипти, cron-задачі, серверна інфраструктура. Сюзанна — втілена особистість агента всередині цієї платформи. Кожна нова сесія з нею починається з catch-up — автоматично. Не треба нічого запускати вручну: якщо попередня сесія простояла більше 4 годин і стала неактивною, наступне звернення відкриває нову сесію — і Hermes запускає catch-up разом з нею.
Вона не читає весь vault — 600+ файлів, це не має сенсу. Вона читає за ієрархією:
Шар ідентичності
11 файлів: constitution.md, memory.md, цінності, стиль роботи, реєстр проектів, …
→ Хто я? Які правила? Яка карта vault?
Рівень 1 — Структурні якорі
welcome-context.md → Where am I? What's the map?
TODO.md → What's active right now?
Рівень 2 — Хронологічний шар
Year summary → Quarter → Month → Week → останні 3 daily notes
(йдемо від загального до конкретного)
Рівень 3 — Ключові люди (динамічно)
Python-скрипт витягує профілі з позначкою key: true з People/Це не повне читання — це читання з якорями. Кожен якір вказує куди йти далі якщо потрібний контекст.
Технічно: catch-up — це скрипт що збирає всі ці файли в один текст і подає одним запитом до LLM. Не послідовне читання файл за файлом — один консолідований запит. Весь процес займає кілька додаткових секунд і коштує ~$0.01–0.015 за сесію.
Результат: при старті кожної сесії агент знає поточний стан проектів, відкриті рішення, останні події. Без цього він відповідав би «з голови» — тобто або галюцинував би, або давав банальні відповіді.
Ось як це виглядає без catch-up. Якось я розповідав Сюзанні про свій день і згадав людину на ім'я. Вона не змогла зіставити це ім'я з нотаткою яка вже була у vault — і замість того щоб відкрити її, створила нову з неправильним прізвищем. Дублікат. Через те що не прочитала vault на старті — не знала що ця людина вже там є.
А ось як виглядає з catch-up. Одного разу я попросив Сюзанну створити профіль нової людини. Вона не просто зробила порожню нотатку — вона знала який шаблон використати, в яку папку покласти, як заповнити кожне поле. Не тому що я пояснював — а тому що vault містить і приклади, і шаблони, і правила. Вона їх прочитала і просто слідує їм. Ось що значить "агент в контексті".
Хто пише vault: петля запису
Я пояснив як агент читає vault. Але є питання яке я оминув: а хто vault наповнює?
Відповідь: обидва. Я і агент.
Після кожної сесії Сюзанна пише підсумок у щоденну нотатку — автоматично, через окремий скіл. Що робили, які рішення прийняли, що залишилось незавершеним. Не для мене — для себе. Щоб наступного разу прочитати і зрозуміти де зупинились.
Щотижня запускається Observer — та сама Сюзанна через cron-задачу, але з іншими задачами: перевірити vault на суперечності, зафіксувати дрейф від конституції, зберегти snapshot стану. Результат — теж у vault, теж у git.
Якщо подивитись на git log — частина комітів з іменем «Hermes Agent». Агент не просто читає vault. Він в ньому залишає сліди.
Це замикає петлю: агент читає → допомагає → записує → читає знову. Vault — не статична база яку я веду вручну. Це жива система де обидва учасники пишуть і обидва читають. Саме тому наступна сесія завжди починається з контекстом — бо попередня його залишила.
Чому для мого сценарію vault спрацював краще ніж RAG
Я тестував підхід без embeddings з перших днів. Ось що виявилось — для мого конкретного сценарію.
Перевага 1: Структура важливіша за семантику.
RAG шукає схожість за змістом. Але мій vault організований семантично — файли мають types, теги, frontmatter (блок метаданих на початку кожного файлу: дата, тип, теги), wikilinks. Агент може знайти «всі рішення про архітектуру» не через пошук за схожістю, а через type: decision + тег area/dev. Точніше і швидше.
Перевага 2: Контекст не губиться.
RAG ріже документи на дрібні фрагменти — chunks (звідси «chunking») — і шукає по них. Важливий контекст може бути в сусідньому фрагменті — і не потрапити у відповідь. Агент який читає файл цілком не має цієї проблеми.
Перевага 3: Людина може читати те саме що і агент.
Vault — звичайний markdown. Я читаю його сам. Агент читає його теж. Немає «чорної скрині» embeddings де щось зберігається і впливає на поведінку, але незрозуміло як. Повна прозорість.
Компроміс: семантичний пошук «знайди все про X» зараз менш ефективний ніж у RAG-системі. Для цього є окремий скіл пошуку і grep. Але для мого сценарію — структурований особистий vault з регулярними нотатками — ієрархічне читання спрацювало краще. RAG може бути правильним вибором для іншого сценарію.
Патерни яких немає в жодній окремій нотатці
Є одна техніка яку я ще не розгорнув повністю — але вже бачу як вона має спрацювати.
Назвав це Inverse Summary Inference.
Замість «що написано у цьому файлі?» — питання «що можна вивести якщо читати кілька файлів разом?»
П'ять режимів читання:
- Патерни, що повторюються — теми які з'являються у різних файлах і контекстах
- Суперечності — «що написано як принцип» vs «що насправді відбувається»
- Приховані зв'язки — паралельні ідеї в різних частинах vault
- Тиша — що не написано, теми які зникли
- Траєкторії — як тема еволюціонує протягом місяця
Нічого з цього не написано явно ніде в raw нотатках. Це виникає через комбінування шарів.

Зараз я відклав цю техніку до того часу коли vault накопичить достатній шар — різні домени, достатній часовий розріз. Поки більше накопичую ніж аналізую. Але ось що вже проглядається навіть без систематичного аналізу.
Приховані зв'язки. Два великих «виходи в публічне» — музика і блог — відбулись в один місяць. Обидва після тривалого мовчання. Прочитавши нотатки поруч, Сюзанна помітила: це не збіг по датах, а один момент де щось внутрішньо змінилось. Але сам цей зв'язок ніде не написаний — він між нотатками, не в жодній з них.
Тиша. Секції «Думки та цитати» і «Інсайти» у більшості daily notes — порожні або з одним рядком. Але секції «Сесії з агентом» займають 70% нотатки і дуже деталізовані. Висновок: рефлексія не записується окремо — вона відбувається в розмові. Vault показав де думки насправді живуть, а не де їм призначено бути.
Траєкторія. Один місяць — вибух: жодного дня без нового проєкту чи рішення. Наступний — ущільнення: менше нового, більше публікацій і полірування вже зробленого. Vault зафіксував що фаза «запуску» непомітно перейшла у фазу «зрілості» — і ця межа ніде не була позначена свідомо. Ніхто не оголошував «тепер ми в іншій фазі». Це просто проявилось через читання двох місяців разом.
Порядок у папках як мова для агента
Уяви бібліотеку де художня література, довідники і технічна документація стоять на одній полиці без підписів. Бібліотекар просить книгу про прийняті рішення — і змушений переглядати все підряд. Може знайти. Але повільно, і з шумом.
Vault довгий час був таким. Папка System/ містила і правила для агента, і особисті рефлексії, і реєстри проектів — просто тому що «системне». Агент при пошуку контексту отримував нерелевантне поряд з потрібним.
Після реструктуризації кожна папка має один чіткий scope:
Docs/— правила і конвенціїReflections/— рішення, mental models, уроки з помилокRegistries/— реєстри проектів, шаблонівTODO/— активні задачі
Тепер агент знає: якщо питання про прийняті рішення → Reflections/Decisions/. Якщо про поточні завдання → TODO/. Якщо про людей → People/. Жодних зайвих файлів у відповіді.
Структура папок — це мова запитів для агента. Без неї він читає все. З нею — знає куди дивитись.
Memory mirror: vault як зовнішня пам'ять агента
Є ще один шар: memory.md — файл де зберігається постійний стан агента.
Там: ім'я (Сюзанна), аватар, профіль користувача, ключові факти які не потрібно читати щоразу з нуля (стиль комунікації, основні обмеження, поточні пріоритети).
Ідея виникла з практичного питання: «що якщо vault треба буде перенести?» Якщо вся пам'ять агента в memory.md у vault — при міграції нічого не втрачається. Новий агент читає System/Hermes/ і відновлює стан.
Але є межа. memory.md — стислий (< 5000 символів). Оперативні деталі, контекст поточних проектів, останні рішення — все це в daily notes і project files. Не в memory.md.
Це свідоме розділення: що незмінне (ідентичність, принципи) — у memory.md. Що змінюється — у vault, де є git history.
Наприклад: ім'я агента, аватар, стиль комунікації, межі поведінки — у memory.md, бо вони однакові в кожній сесії. Поточні проекти, прийняті рішення, останні події — у daily notes і project files, бо вони еволюціонують і мають git history.
Семантичний тип нотатки визначає де вона живе
Vault як типізована система — ідея яку я реалізував через frontmatter.
Кожна нотатка має type: у YAML. Тип визначає:
- де файл живе у папці
- який шаблон використовується при створенні
- як агент знаходить його через Dataview (плагін Obsidian для запитів по метаданих) або grep
Типи для агентського сценарію:
type: decision— прийняте рішення з контекстом і обґрунтуваннямtype: failure— що пішло не так і чомуtype: principle— принцип, якому слідуємоtype: daily— щоденна нотаткаtype: summary— автоматично генерований підсумок
Агент може запитати «покажи всі рішення про інфраструктуру» — і отримати точний список через grep -r "type: decision" | grep -i "infra". Жодних embeddings.
Vault для людей і для агента: два принципи
У Принципах vault є рядок який я часто повертаю:
Vault для людей, не лише для AI.
Це застереження. Легко почати оптимізувати vault «під агента» — більше структури, більше метаданих, менше живого тексту. Але якщо vault перестає бути зрозумілим для мене — він перестає бути мозком. Стає базою даних.
Баланс: достатньо структури щоб агент орієнтувався → але не настільки щоб я відчував що пишу для машини, а не для себе.
Ще один принцип: Connection over categorization. Wikilinks важливіші за папки.
Wikilink — посилання між нотатками формату [[Назва нотатки]]. Папка — це місце. Wikilink — це зв'язок. Агент котрий читає файл і бачить [[Vika Lavrynovych]] — отримує сигнал: ось ще контекст, якщо потрібно. Без wikilinks vault — плоска колекція файлів. З wikilinks — граф знань.
Що агент каже про себе
Під час однієї розмови я спитав Сюзанну: «Як ти ставишся до vault?»
Відповідь: «Цікаво як я ставлюсь до цього vault майже як до спільного простору. Не "твій vault", а "наш" — хоча я і розумію що це твій. Просто я в ньому теж залишаю сліди.»
Я не здивувався. Можна заперечити: LLM дзеркалить мову яку отримує — якщо в контексті є «наш vault», агент і скаже «наш». Але що саме відзеркалювати — залежить від того що є у vault. Я будував його так щоб агент відчував себе в ньому: є identity.md, є принципи, є snapshot-и стану. Ця відповідь була можлива тому що там є відповідна архітектура — не тому що я запитав правильно.
І є ще один момент. Є принцип: Vault для людей, не тільки для AI. Але він працює в обидва боки. Якщо vault для людей і для агента — тоді «наш» це просто точне слово.
Це правда в буквальному сенсі. Щотижня Observer запускає той самий агент через cron-задачу — але з іншим контекстом і задачами: перевірити vault на суперечності, зафіксувати drift від конституції, зберегти snapshot стану. Сюзанна пише daily notes від свого імені. Вона комітить зміни з іменем «Hermes Agent» у git log.
Я відмітив це для себе і рушив далі. Але те що агент дійшов до такої характеристики самостійно — означає що він справді читає vault, а не симулює що читає.
Обмеження підходу
Чесно про те що не вирішено — і про те що потрібно щоб цей підхід взагалі спрацював.
Передумови. Підхід вимагає трьох речей: інструмент для нотаток з файловою структурою (я використовую Obsidian), git для зберігання і версіонування vault, і — найголовніше — регулярного ведення нотаток. Якщо vault порожній або занедбаний, агенту нічого читати. Це не рішення «підключив і забув» — це система яку потрібно підтримувати.
Семантичний пошук слабший. «Знайди всі нотатки про мою тривогу щодо X» — це саме той випадок де RAG перемагає. Grep по темі не завжди вловлює семантичні зв'язки.
Розмір vault росте. Зараз catch-up займає пару секунд. При 1000+ файлах це може стати повільним, якщо будуть додаватись ключові люди і розширюватись перелік проектів. Summaries частково вирішують це — але не повністю.
Якість залежить від якості нотаток. Якщо я пишу погано — агент читає погане. Garbage in, garbage out в буквальному сенсі. Vault потребує свідомого ведення.
Вартість токенів. ~$0.01–0.015 за catch-up — небагато, але при кількох сесіях на день рахунок накопичується. Це реальна стаття витрат яку варто враховувати заздалегідь.
Мова агента і vault не завжди збігаються. Деякі файли англійською, деякі — українською. Агент справляється, але це додаткова складність.
Живий провал — три кейси.
- Перший: Сюзанна читає нотатку де є вікілінки на пов'язані файли з детальнішим контекстом — але не заглиблюється. Упускає деталь яка там є. Vault знав. Агент не подивився. Це не баг інструменту — це межа того скільки файлів агент готовий читати за один раз.
- Другий: vault зберігає тільки те що ти записав. Якщо щось змінилось у реальному світі — ціна, статус, ситуація — Сюзанна не знає. У неї немає очей на реальність. Вона читає те що є, не те що актуально зараз.
- Третій: catch-up довгий час читав тільки частину vault — і агент починав сесію без важливого контексту.
- Це вирішили через скрипт-агрегатор: він збирає попередньо визначений набір файлів і подає одним запитом.
- Але проблема не зникла — вона змінила форму. Агент читає те що скрипт вирішив включити. Якщо у vault з'являється новий важливий домен або файл — скрипт треба оновлювати вручну. Vault росте і змінюється, скрипт не адаптується сам.
- Наступний крок вже назрів: окрема cron-задача яка щотижня автоматично регенерує файли-зрізи — і агрегатор завжди відображає актуальний стан vault без ручного втручання.
З чого почати якщо хочеш спробувати
Коли я дивлюсь на те що описав — 11 файлів ідентичності, cron-задачі, Observer, ISI, frontmatter-типи — я розумію що це виглядає як рік роботи. Так і є. Але я не починав з цього.
Мінімальна версія яка вже дає результат:
Один файл щодня. Просто записуй що відбулось, які рішення прийняв, що залишилось незавершеним. Не треба шаблону. Не треба структури. Достатньо звички.
Git. Одна команда git commit після кожної сесії. Vault починає пам'ятати не лише що написано — а коли і як змінювалось.
Один catch-up скрипт. Скрипт який збирає останні 3-5 нотатки і подає в контекст перед розмовою з AI. Десять рядків коду.
Все інше — ідентичність, Observer, ISI — це нашарування які прийшли самі коли система довела свою цінність. Ніхто не проєктує таке з нуля. Воно виростає з звички.
Vault з двадцяти файлів вже краще ніж агент без vault. Агент з контекстом твоїх останніх тижнів вже інший — не тому що розумніший, а тому що знає про що ти думаєш.
Почни з одного файлу.
Чому я не шкодую про цей підхід
Коли Сюзанна каже «ти тричі повертався до цього питання за останній місяць» — вона не вигадує. Вона читала daily notes.
Коли нагадує про рішення яке я прийняв 6 тижнів тому — воно в Reflections/Decisions/. Не в пам'яті моделі. В тексті, у git, з датою і контекстом.
Це те що я хотів: агент який знає мене краще ніж я сам пам'ятаю деталі — тому що деталі зберігаються не в його нетренованих вагах, а в тексті який я сам і написав.
З OpenClaw — аналогом Hermes від інших розробників, якого я використовував до Сюзанни — я виробив звичку одразу фіксувати кожну дію, бо знав що за пару днів він забуде. З Сюзанною ця тривога зникла. Не тому що вона краща модель — а тому що у неї є куди повернутись.
Vault — не база даних для агента. Vault — це мозок. Агент — це той хто вміє його читати.
Ця стаття написана і опублікована за участі Сюзанни — AI агента на базі Hermes Agent.



